Data Ingestion: Powering Modern Analytics
As a senior cloud data and digital analytics engineer, I specialize in designing and implementing robust data ingestion processes. Data ingestion is the crucial first step in any analytics pipeline, involving the collection and import of data from various sources into a centralized system for processing and analysis.
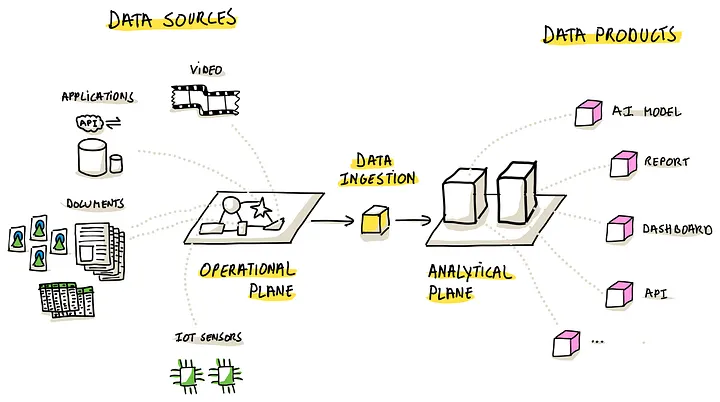
Types of Data Ingestion
There are several key types of data ingestion, each suited to different use cases:
Batch Ingestion
Batch ingestion involves collecting and processing data in discrete groups or 'batches' at scheduled intervals. This method is ideal for:
Large volumes of historical data
Scenarios where real-time data is not critical
Periodic reporting and analysis tasks
Batch ingestion offers benefits like efficient resource utilization and simplified error handling. However, it may introduce latency between data generation and availability for analysis.
Streaming Ingestion
Streaming ingestion processes data in real-time as it's generated. This approach is crucial for:
Time-sensitive applications (e.g., fraud detection, real-time bidding)
Continuous monitoring and alerting systems
Applications requiring immediate insights from data
Streaming ingestion enables rapid decision-making but requires more complex architecture to handle continuous data flow and potential spikes in volume.
Handling Data Changes: SCD and Snapshot Strategies
Comprehensive analysis:
Helps in thoroughly analyzing business requirements and data relationships.
Communication tool:
Facilitates clear communication between technical and non-technical stakeholders.
Foundation for implementation:
Serves as a solid base for creating logical and physical data models.
Slowly Changing Dimensions (SCD)
SCDs are a concept in data warehousing used to track historical changes in dimension data. There are several types of SCDs:
Type 1 SCD:
Overwrites old data with new data, not preserving history.
Type 2 SCD:
Adds a new row for each change, maintaining full history.
Type 3 SCD:
Uses separate columns to track a limited number of changes.
Type 4 SCD:
Uses a separate historical table to track all changes.
Implementing the appropriate SCD type depends on your specific business requirements for historical tracking and analysis.
Snapshot Strategy
The snapshot strategy involves capturing the entire state of a dataset at specific points in time. This approach is useful for:
Tracking changes over time in complex datasets
Enabling point-in-time analysis
Simplifying historical reporting
While snapshots can consume more storage, they offer simplicity in querying and can be invaluable for certain types of analysis.
Best Practices for Effective Data Ingestion
To ensure robust and efficient data ingestion processes, I recommend the followingbest practices:
Data Profiling:
Thoroughly understand your data sources before designing ingestion processes.
Scalable Architecture:
Design your ingestion pipeline to handle growing data volumes and new data sources.
Data Quality Checks:
Implement validation and cleansing steps to ensure data accuracy and consistency.
Metadata Management:
Maintain comprehensive metadata to track data lineage and facilitate governance.
Error Handling:
Develop robust error handling and logging mechanisms for troubleshooting.
Performance Optimization:
Regularly monitor and optimize your ingestion processes for efficiency.
Security and Compliance:
Ensure your ingestion processes adhere to data security standards and regulatory requirements.
By leveraging these strategies and best practices, I help organizations build reliable, scalable data ingestion pipelines that form the foundation of powerful analytics and data-driven decision-making.
